WavTokenizer: SOTA токенизатор аудио
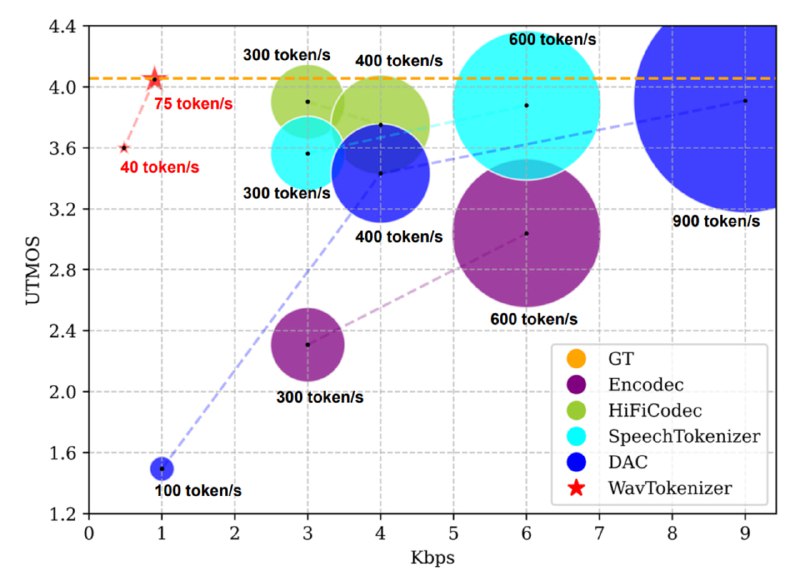
Кажется, это прорыв. Ему хватает всего 75 токенов в секунду, чтобы поставить рекорд в качестве реконструкции речи. При этом всё работает довольно сносно и для 45 ток/с. Предыдущие решения даже близко не стояли!
Как авторам это удалось? Просто набор удачных технических трюков поверх Encodec:
- отказались от dilated conv в декодере в пользу Fourier Transform
- расширили окно внимания до 3 сек
- оптимальная инициализация кодбука через k-means
- единый квантайзер вместо иерархического
- большой словарь аудио-токенов (2^12)
Такие токенизаторы используются для Text-to-Speech моделей, для мультимодальных LLM (GPT-4o) и для генерации музыки. Код и веса в открытом доступе.
Статья, GitHub, demo, Hugging Face
Кажется, это прорыв. Ему хватает всего 75 токенов в секунду, чтобы поставить рекорд в качестве реконструкции речи. При этом всё работает довольно сносно и для 45 ток/с. Предыдущие решения даже близко не стояли!
Как авторам это удалось? Просто набор удачных технических трюков поверх Encodec:
- отказались от dilated conv в декодере в пользу Fourier Transform
- расширили окно внимания до 3 сек
- оптимальная инициализация кодбука через k-means
- единый квантайзер вместо иерархического
- большой словарь аудио-токенов (2^12)
Такие токенизаторы используются для Text-to-Speech моделей, для мультимодальных LLM (GPT-4o) и для генерации музыки. Код и веса в открытом доступе.
Статья, GitHub, demo, Hugging Face