Llama-3
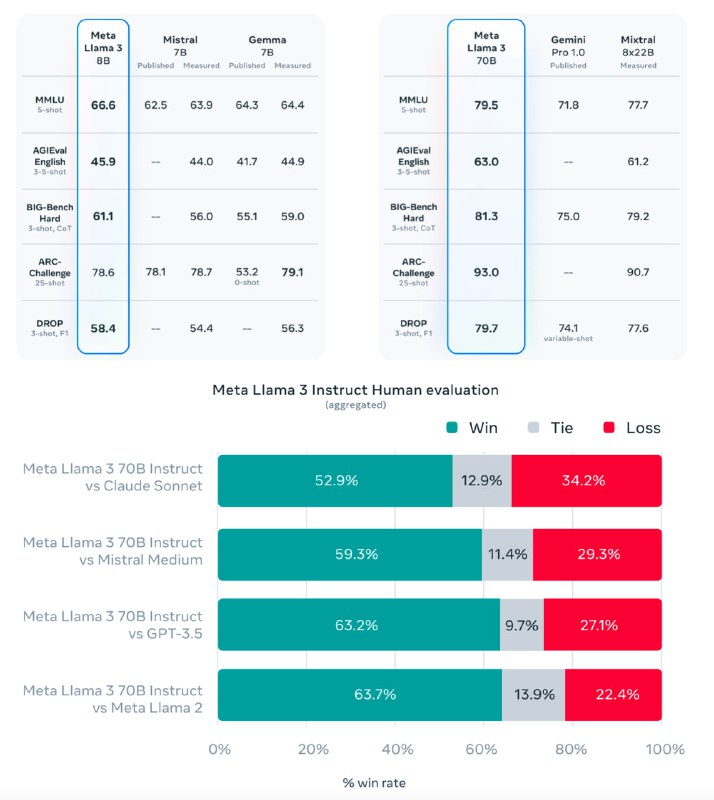
Есть версии на 8B и 70B параметров. По сравнению с прошлой ламой тут теперь побольше словарь — 128k токенов вместо 32k (думаю отсюда и +1B параметров). А также добавили grouped query attention (GQA), чтобы это работало быстрее.
Во время обучения модели скормили 15Т токенов, это офигеть как много (по шиншилле можно и 200B версию на таком сете обучать).
Блог, веса
Есть версии на 8B и 70B параметров. По сравнению с прошлой ламой тут теперь побольше словарь — 128k токенов вместо 32k (думаю отсюда и +1B параметров). А также добавили grouped query attention (GQA), чтобы это работало быстрее.
Во время обучения модели скормили 15Т токенов, это офигеть как много (по шиншилле можно и 200B версию на таком сете обучать).
Блог, веса