Quiet-STaR: думательные токены вместо Chain-of-Thought
Очень интересная идея, как обобщить CoT-промптинг, приближая его к подобию мыслительного процесса человека (говорить не всё, что думаешь).
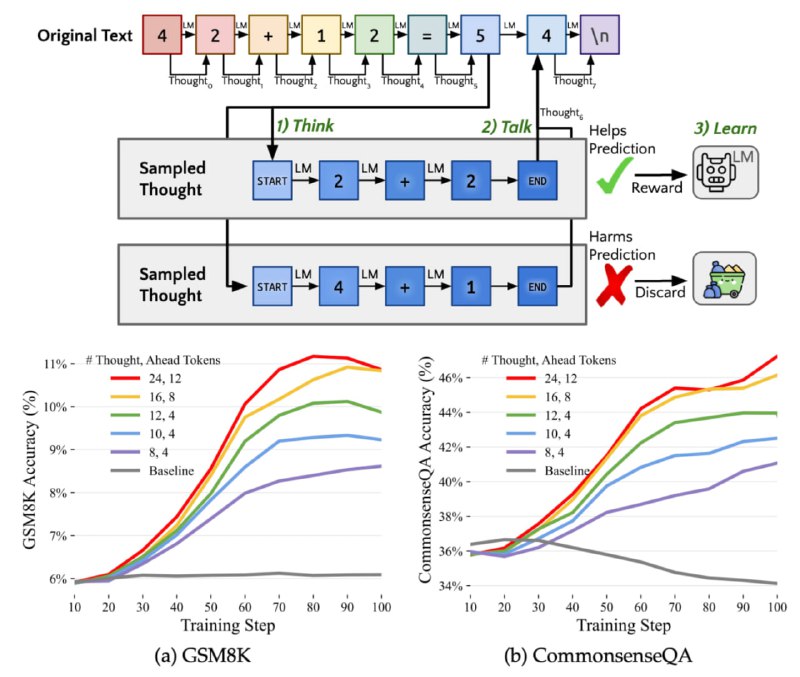
Для этого авторы предложили позволить LLM иногда «думать», — старт и конец такой мысли определяются обучаемыми RL спецтокенами, а вот сама мысль чаще всего состоит из какой-то белиберды, уменьшающей перплексию дальнейшего текста.
В отличие от CoT, тут нет требования писать внятно, поэтому то, что генерится внутри мысли далеко не всегда получается интерпретировать. Тем не менее, это сильно бустит метрики и практически не замедляет инференс, т.к. генерация идёт параллельно.
Понятное дело, что это не работает без дообучения, но я попросил чатгпт притвориться, что она использует эти мыслительные токены, и спросил её помогло ли это ответить на мой вопрос. Она сказала что помогло 😁
Статья
Очень интересная идея, как обобщить CoT-промптинг, приближая его к подобию мыслительного процесса человека (говорить не всё, что думаешь).
Для этого авторы предложили позволить LLM иногда «думать», — старт и конец такой мысли определяются обучаемыми RL спецтокенами, а вот сама мысль чаще всего состоит из какой-то белиберды, уменьшающей перплексию дальнейшего текста.
В отличие от CoT, тут нет требования писать внятно, поэтому то, что генерится внутри мысли далеко не всегда получается интерпретировать. Тем не менее, это сильно бустит метрики и практически не замедляет инференс, т.к. генерация идёт параллельно.
Понятное дело, что это не работает без дообучения, но я попросил чатгпт притвориться, что она использует эти мыслительные токены, и спросил её помогло ли это ответить на мой вопрос. Она сказала что помогло 😁
Статья