Галлюцинации LLM можно определять по внутренней размерности активаций (by CISCO)
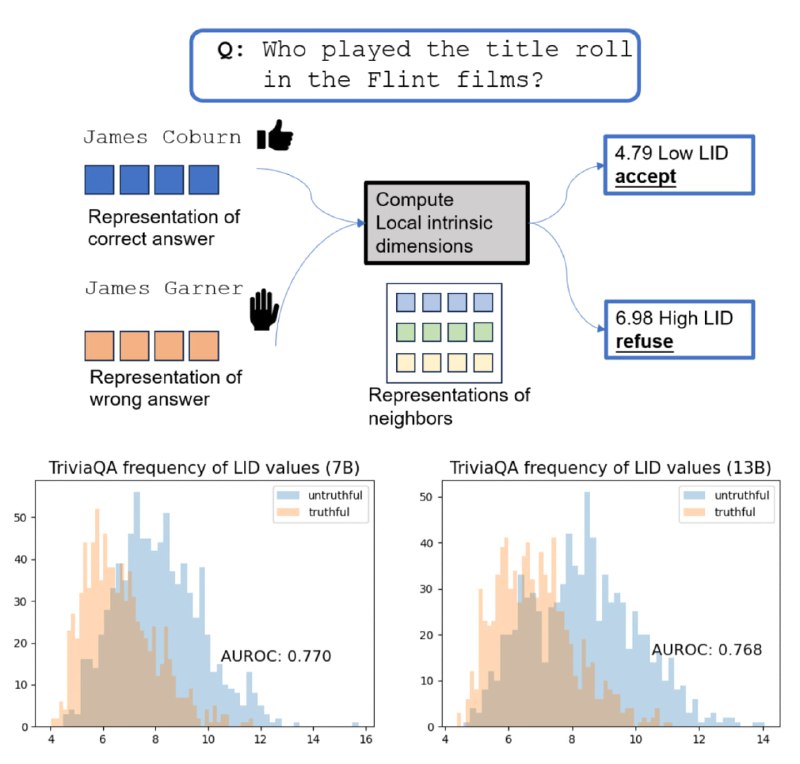
На мой взгляд один из самых красивых и простых способов выявлять враньё языковых моделей. Внутренняя размерность активаций — это что-то вроде сложности манифолда на котором лежат промежуточные эмбеддинги (кину в комменты пример).
И вот оказывается, когда LLM выдумывает что-то несуществующее, то размерность эмбеддингов со средних слоёв значительно подрастает (см. гистограммы). Таким образом, по всплескам размерности можно определить, где именно модель галлюцинирует, а где говорит правду.
Статья
На мой взгляд один из самых красивых и простых способов выявлять враньё языковых моделей. Внутренняя размерность активаций — это что-то вроде сложности манифолда на котором лежат промежуточные эмбеддинги (кину в комменты пример).
И вот оказывается, когда LLM выдумывает что-то несуществующее, то размерность эмбеддингов со средних слоёв значительно подрастает (см. гистограммы). Таким образом, по всплескам размерности можно определить, где именно модель галлюцинирует, а где говорит правду.
Статья