SliceGPT: сжимаем LLM, уменьшая размерность эмбеддингов (by Microsoft)
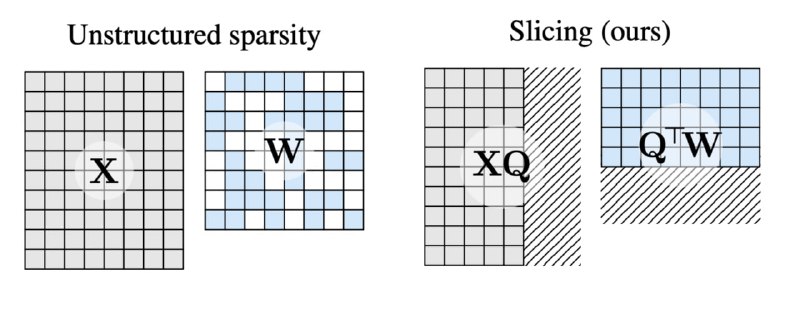
Языковые модели обладают избыточной, не используемой ёмкостью — что-то похожее мы уже видели в статье про мёртвые нейроны. А тут авторы предлагают убрать всё лишнее ортогональными преобразованиями с последующим отбрасыванием малоактивных строк и столбцов из матриц весов.
Выглядит это так, будто бы размерность эмбеддингов итоговой модели стала на 10-30% меньше, а перплексия и метрики почти не ухудшаются, особенно у крупных моделей (Llama-70B и OPT-66B). При этом в коде инференса ничего менять не надо.
P.S. Забавно, но модели вроде Phi-2 сжимаются гораздо менее охотно, возможно они эффективнее используют свою ёмкость.
Статья, GitHub (soon)
Языковые модели обладают избыточной, не используемой ёмкостью — что-то похожее мы уже видели в статье про мёртвые нейроны. А тут авторы предлагают убрать всё лишнее ортогональными преобразованиями с последующим отбрасыванием малоактивных строк и столбцов из матриц весов.
Выглядит это так, будто бы размерность эмбеддингов итоговой модели стала на 10-30% меньше, а перплексия и метрики почти не ухудшаются, особенно у крупных моделей (Llama-70B и OPT-66B). При этом в коде инференса ничего менять не надо.
P.S. Забавно, но модели вроде Phi-2 сжимаются гораздо менее охотно, возможно они эффективнее используют свою ёмкость.
Статья, GitHub (soon)