The Shape of Learning: Intrinsic Dimensions in Transformer-Based Models
Препринт нашей новой работы! Оказалось, что языковые модели «упаковывают» свои репрезентации в очень маленькое пространство с внутренней размерностью не больше 60. И при этом анизотропия на средних слоях трансформеров-декодеров стремится к единице! Получается, эмбеддинги из середины модели расположены вдоль одной линии.
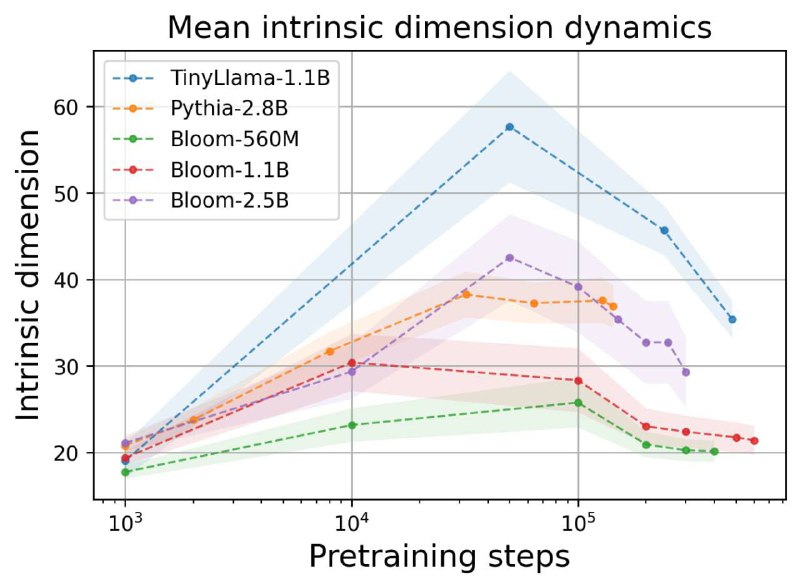
Еще одно интересное наблюдение — обучение LLM делится на две фазы: расширение и последующее сжатие активаций (см. картинку). А перед взрывами лосса их размерность немного подрастает.
UPD: приняли на EACL 🎉
Статья
Препринт нашей новой работы! Оказалось, что языковые модели «упаковывают» свои репрезентации в очень маленькое пространство с внутренней размерностью не больше 60. И при этом анизотропия на средних слоях трансформеров-декодеров стремится к единице! Получается, эмбеддинги из середины модели расположены вдоль одной линии.
Еще одно интересное наблюдение — обучение LLM делится на две фазы: расширение и последующее сжатие активаций (см. картинку). А перед взрывами лосса их размерность немного подрастает.
UPD: приняли на EACL 🎉
Статья