Direct Preference Optimization: Your Language Model is Secretly a Reward Model
arxiv.org/abs/2305.18290
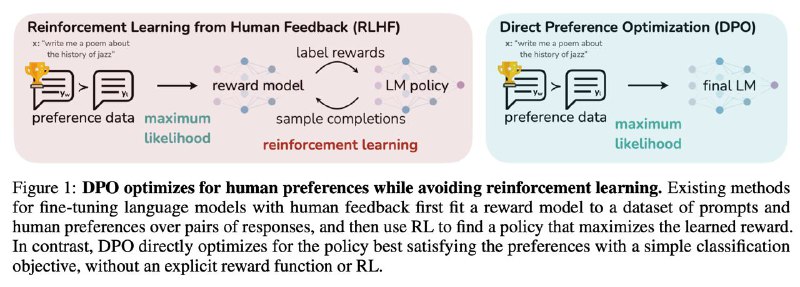
Интересная статья, которая предлагает делать RLHF без RL. Используя пару математических трюков, можно показать что при модели Bradley-Terry человеческих предпочтений (которая похожа на то как моделируется reward в RLHF) можно вывести определённый лосс L который нам надо минимизировать.
Таким образом мы сводим RL задачу которая оптимизирует выученный (произвольный) reward к прямой задачи оптимизации на нашем датасете человеческих предпочтений. На практике это означает, что вам больше не надо страдать с PPO, не нужно генерировать текст во время обучения, и можно просто напрямую оптимизировать L. Экспериментальные результаты показывают что DPO работает так же как RLHF или лучше.
arxiv.org/abs/2305.18290
Интересная статья, которая предлагает делать RLHF без RL. Используя пару математических трюков, можно показать что при модели Bradley-Terry человеческих предпочтений (которая похожа на то как моделируется reward в RLHF) можно вывести определённый лосс L который нам надо минимизировать.
Таким образом мы сводим RL задачу которая оптимизирует выученный (произвольный) reward к прямой задачи оптимизации на нашем датасете человеческих предпочтений. На практике это означает, что вам больше не надо страдать с PPO, не нужно генерировать текст во время обучения, и можно просто напрямую оптимизировать L. Экспериментальные результаты показывают что DPO работает так же как RLHF или лучше.