🔥QLoRA: Зафайнтюнить 30B модель в колабе? Легко!
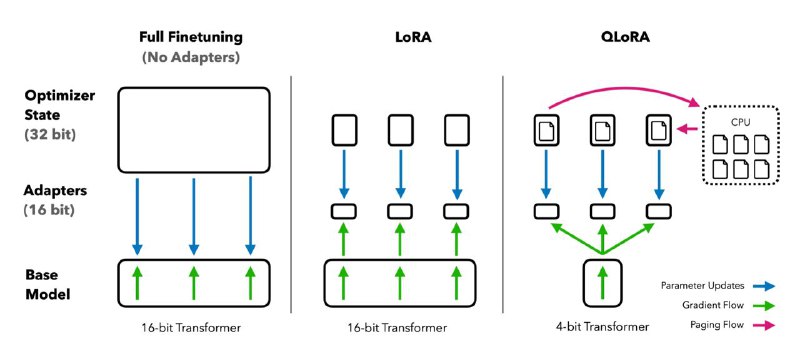
Гениальная и удивительно простая идея лежит в основе этого подхода. Если мы тюним только LoRA адаптеры, а основная модель заморожена, то почему-бы не заквантовать её до предела?
Квантуется модель в новый 4-bit NormalFloat, который отлично подходит для normally distributed активаций. При этом все операции с LoRA остаются в bf16. Самое удивительное — такой подход не отстаёт от полного 16-bit файнтюнига базовой модели — авторы проверили на 1000(!) разных LM.
Всё это уже интегрировано в HuggingFace, а как бонус — авторы обучили нового SOTA чатбота (Guanaco + OASST1 + QLoRA).
Статья, GitHub, colab, модель
Гениальная и удивительно простая идея лежит в основе этого подхода. Если мы тюним только LoRA адаптеры, а основная модель заморожена, то почему-бы не заквантовать её до предела?
Квантуется модель в новый 4-bit NormalFloat, который отлично подходит для normally distributed активаций. При этом все операции с LoRA остаются в bf16. Самое удивительное — такой подход не отстаёт от полного 16-bit файнтюнига базовой модели — авторы проверили на 1000(!) разных LM.
Всё это уже интегрировано в HuggingFace, а как бонус — авторы обучили нового SOTA чатбота (Guanaco + OASST1 + QLoRA).
Статья, GitHub, colab, модель