TinyStories: The Smallest GPT with Coherent English (by Microsoft)
Как думаете, с какого размера у LM появляется возможность писать связный текст? Оказалось, что и 2.5M параметров достаточно!
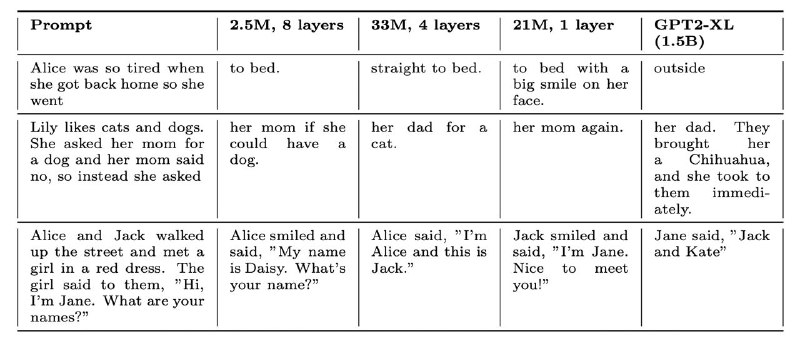
Главное препятствие для полноценного понимания языка у трансформеров — огромное количество редких слов (длинный хвост распределения). Но если составить обучающий датасет из 1.5к наиболее частотных корней (словарный запас 5-летнего ребёнка), то даже однослойную GPT можно будет обучить так, что она обойдёт GPT2-XL!
Этот чудесный датасет, написанный руками GPT-4, отлично подходит для валидации новых архитектур, на нём даже скейлинг Шиншиллы подтверждается. Так что если хотите изобрести свою «SuperGPT» архитектуру, то рекомендую экспериментировать на этом сете. Его размер всего 3 Гб.
P.S. Из интересных выводов — лучше масштабировать GPT в глубину, чем в ширину.
Статья, датасет, модель
Как думаете, с какого размера у LM появляется возможность писать связный текст? Оказалось, что и 2.5M параметров достаточно!
Главное препятствие для полноценного понимания языка у трансформеров — огромное количество редких слов (длинный хвост распределения). Но если составить обучающий датасет из 1.5к наиболее частотных корней (словарный запас 5-летнего ребёнка), то даже однослойную GPT можно будет обучить так, что она обойдёт GPT2-XL!
Этот чудесный датасет, написанный руками GPT-4, отлично подходит для валидации новых архитектур, на нём даже скейлинг Шиншиллы подтверждается. Так что если хотите изобрести свою «SuperGPT» архитектуру, то рекомендую экспериментировать на этом сете. Его размер всего 3 Гб.
P.S. Из интересных выводов — лучше масштабировать GPT в глубину, чем в ширину.
Статья, датасет, модель