Wikipedia-based Image Text Datasets (by Google)
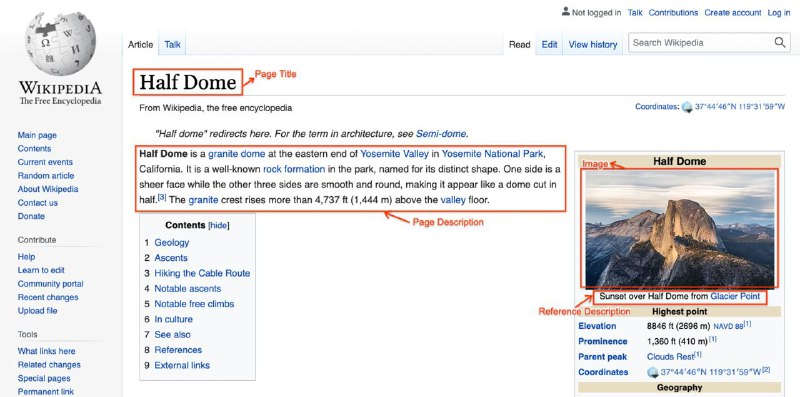
Представлены два крупнейших чистых мультимодальных датасета: WIT и WikiWeb2M — они содержат полные страницы википедии со всеми картинками, структурированным текстом и метадатой (37M изображений и 1.8М страниц).
Они идеально подходят для обучения таких штук как Flamingo или Fromage, а также отлично сочетаются с графами знаний.
Статья, WIT, WikiWeb2M
Представлены два крупнейших чистых мультимодальных датасета: WIT и WikiWeb2M — они содержат полные страницы википедии со всеми картинками, структурированным текстом и метадатой (37M изображений и 1.8М страниц).
Они идеально подходят для обучения таких штук как Flamingo или Fromage, а также отлично сочетаются с графами знаний.
Статья, WIT, WikiWeb2M