Emergent Abilities of LLM — это всего лишь иллюзия (by Stanford)
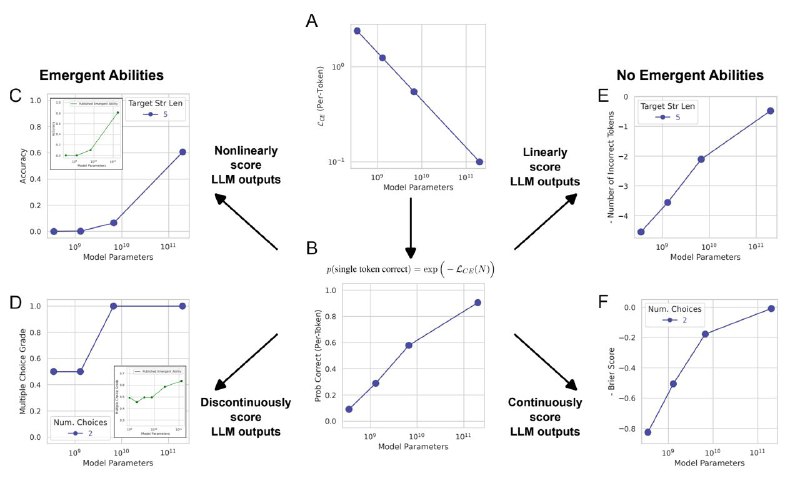
Последнее время много говорят про эмерджентность гигантских языковых моделей — мол, некоторые их свойства(проблески сознания 😂) начинают резко проявляться на большом масштабе (~30B параметров). Но тут обнаружили, что это всего лишь следствие выбора сильно нелинейных метрик для тестирования (Multiple Choice Grade, String Accuracy). И если их поменять на более «плавные» аналоги (Brier Score, Edit Distance) — то вся эмерджентность куда-то пропадает и перформанс LLM масштабируется без резких скачков.
Авторы демонстрируют эту псевдо-эмерджентность на всём семействе моделей instructGPT/GPT-3 и даже на классических автоэнкодерах для MNIST. Похоже, что всё-таки никакого магического числа параметров для языковых моделей не существует, и все их свойства меняются постепенно и крайне предсказуемо.
Статья
Последнее время много говорят про эмерджентность гигантских языковых моделей — мол, некоторые их свойства
Авторы демонстрируют эту псевдо-эмерджентность на всём семействе моделей instructGPT/GPT-3 и даже на классических автоэнкодерах для MNIST. Похоже, что всё-таки никакого магического числа параметров для языковых моделей не существует, и все их свойства меняются постепенно и крайне предсказуемо.
Статья