Почему Adam иногда взрывается при обучении больших LM? (by META)
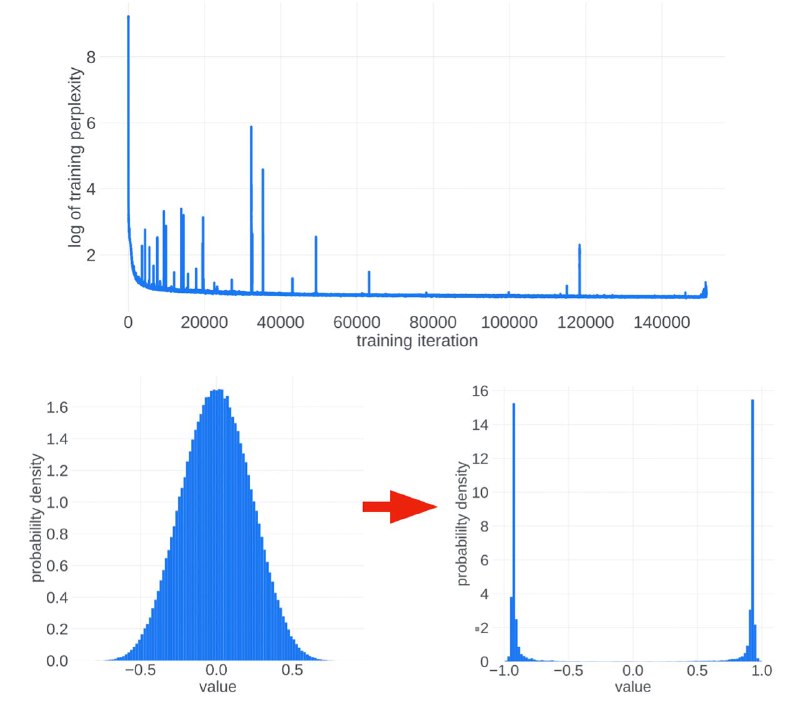
Очень тяжело учить гигантские языковые модели, к примеру, PaLM приходилось перезапускать десятки раз! И откатывать модель на сотни батчей назад из-за возникающих всплесков перплексии. Чтобы найти причины такой нестабильности, авторы провели кучу экспериментов и даже подвели теорию под всё это.
Главную вину возложили на оптимизатор Adam — оказалось, что при обучении больших моделей (от 60B параметров) возникает корреляция градиентов между разными степами. Это нарушает условия Центральной Предельной Теоремы, из-за чего распределение апдейтов весов становится бимодальным (см. картинку), а такие апдейты почти всегда ортогональны истинному направлению оптимизации. Именно это движение «вбок» и приводит к взрыву.
В конце статьи предлагается несколько способов как этого избежать, но единственный надёжный — откат модели на несколько шагов назад.
Статья
Очень тяжело учить гигантские языковые модели, к примеру, PaLM приходилось перезапускать десятки раз! И откатывать модель на сотни батчей назад из-за возникающих всплесков перплексии. Чтобы найти причины такой нестабильности, авторы провели кучу экспериментов и даже подвели теорию под всё это.
Главную вину возложили на оптимизатор Adam — оказалось, что при обучении больших моделей (от 60B параметров) возникает корреляция градиентов между разными степами. Это нарушает условия Центральной Предельной Теоремы, из-за чего распределение апдейтов весов становится бимодальным (см. картинку), а такие апдейты почти всегда ортогональны истинному направлению оптимизации. Именно это движение «вбок» и приводит к взрыву.
В конце статьи предлагается несколько способов как этого избежать, но единственный надёжный — откат модели на несколько шагов назад.
Статья