Дропаут ускоряет обучение глубоких моделей (by META)
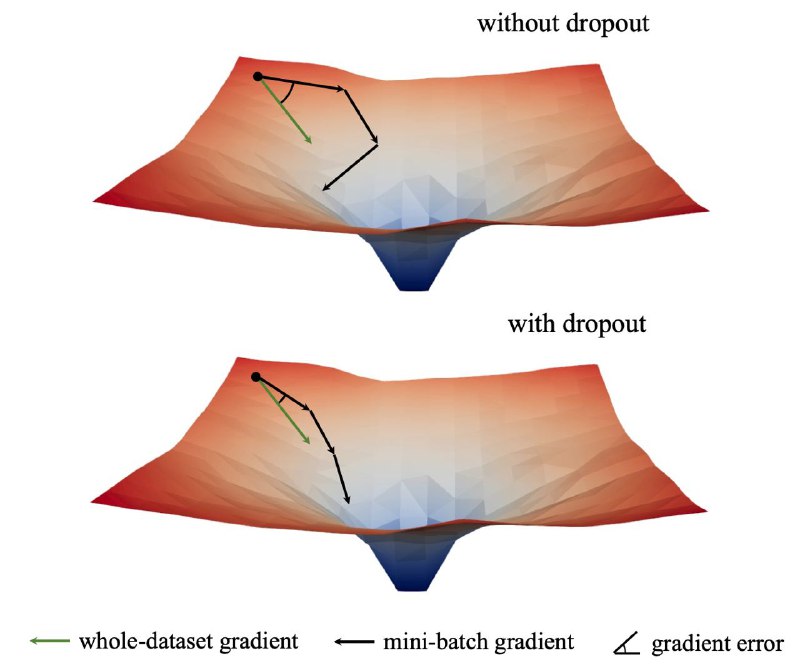
Раньше считалось, что с дропаутом лосс наоборот падает медленнее, и это своего рода цена за спасение от переобучения — но оказалось, что это не так.
Eсли применять дропаут только в самом начале обучения, а потом отключать, то можно не только спастись от оверфиттинга, но и ускорить сходимость модели!
Это позволяет лучше синхронизировать градиенты на large-scale датасетах, что приводит к стабильному long-term выигрышу на всех архитектурах.
Статья, GitHub
Раньше считалось, что с дропаутом лосс наоборот падает медленнее, и это своего рода цена за спасение от переобучения — но оказалось, что это не так.
Eсли применять дропаут только в самом начале обучения, а потом отключать, то можно не только спастись от оверфиттинга, но и ускорить сходимость модели!
Это позволяет лучше синхронизировать градиенты на large-scale датасетах, что приводит к стабильному long-term выигрышу на всех архитектурах.
Статья, GitHub