Memorizing Transformers: как добавить в GPT долговременную память (by Google)
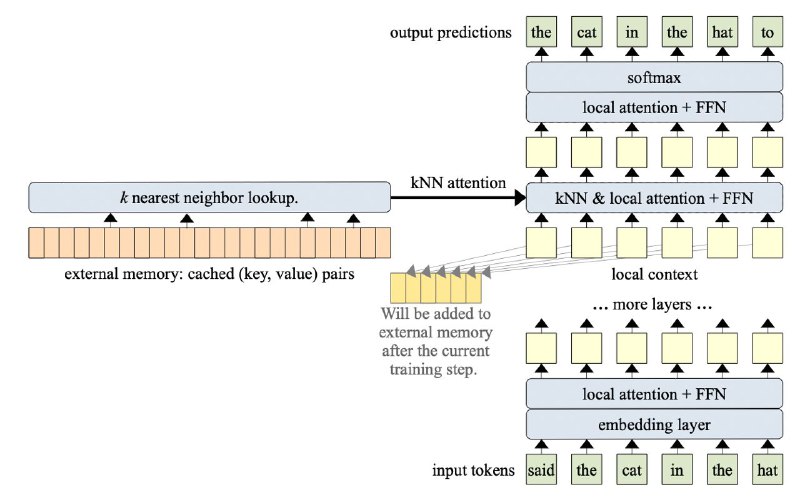
Вы думали, что 260 000 токенов это что-то невозможное для этэншна? А вот и нет, оказывается, если приделать approximate KNN внутрь механизма внимания и складировать Keys и Values в отдельном буфере, то можно засунуть в GPT целые книги!
Авторы показывают, что такое внимание помогает модели вспоминать сложные теоремы и леммы, которые были описаны десятки страниц назад! А самое крутое — это можно приделать к любому предобученному трансформеру, нужно лишь немного потюнить его на длинных текстах, что не очень сложно, так как градиенты через память не идут.
Статья
Вы думали, что 260 000 токенов это что-то невозможное для этэншна? А вот и нет, оказывается, если приделать approximate KNN внутрь механизма внимания и складировать Keys и Values в отдельном буфере, то можно засунуть в GPT целые книги!
Авторы показывают, что такое внимание помогает модели вспоминать сложные теоремы и леммы, которые были описаны десятки страниц назад! А самое крутое — это можно приделать к любому предобученному трансформеру, нужно лишь немного потюнить его на длинных текстах, что не очень сложно, так как градиенты через память не идут.
Статья