🔥FlexGen: как запустить OPT-175B на своём ноутбуке
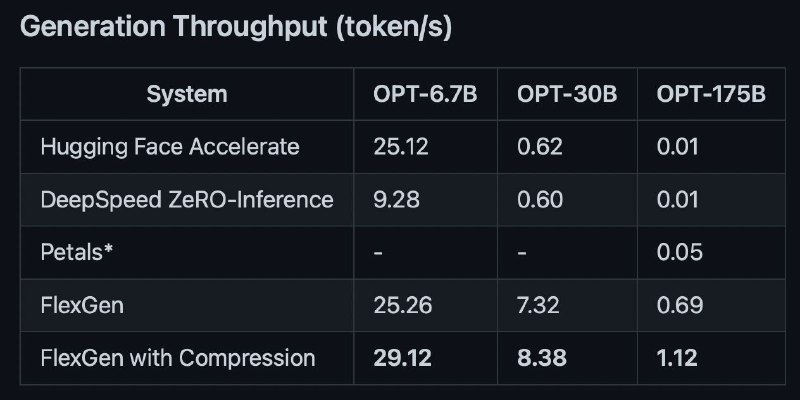
Просто восторг! Самую большую открытую языковую модель теперь можно запустить на одной 16GB GPU и при этом не ждать генерацию целую вечность — скорость 1 токен в секунду!
Причём ускорение и сжатие модели делается очень просто:
P.S. В их репозитории даже есть пример чатбота на основе OPT-66B
Статья, GitHub
Просто восторг! Самую большую открытую языковую модель теперь можно запустить на одной 16GB GPU и при этом не ждать генерацию целую вечность — скорость 1 токен в секунду!
Причём ускорение и сжатие модели делается очень просто:
model = OptLM(model)P.S. В их репозитории даже есть пример чатбота на основе OPT-66B
Статья, GitHub