Совсем недавно вышла бета версия библиотеки TorchMultimodal (ссылка), в которой авторы постарались собрать все лучшие техники и фичи обучения SoTA мультизадачных мультимодальных (М2) архитектур:
Всё это позволит ставить быстрые и удобные эксперименты для обучения М2 моделей.
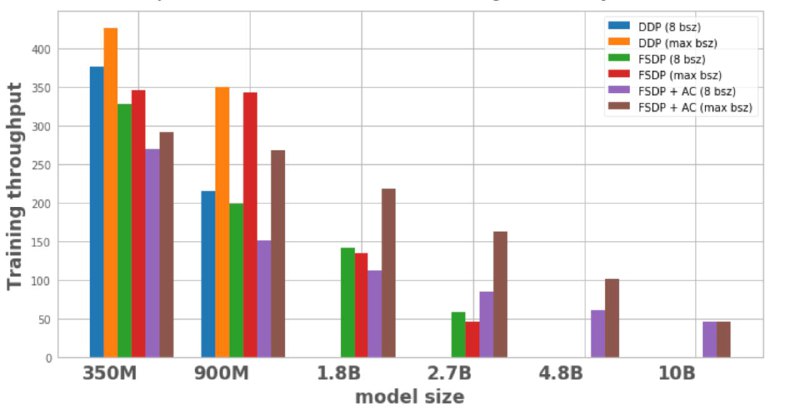
В довесок авторы сделали интересный пост о распределённом обучении (ссылка), где на примере модели FLAVA (мультимодальный late fusion трансформер) показали, как можно её масштабировать с 350M параметров до 10B. Рассмотрели два ключевых подхода:
1. Distributed Data Parallel - нарезка датасета по воркерам, градиенты синхронизируются ДО обновления весов, по сути вся модель «реплицируется»
2. Fully Sharded Data Parallel - параметры, градиенты и состояния оптимизатора нарезаются (шардируются) по воркерам (а-ля ZeRO-3), перед forward и backward propagation шарды объединяются.
Сравнение производительности (среднее число сэмплов в секунду за исключением первых 100 на warmup) можно оценить на графике.
github
статья про TorchMultimodal
статья про Scaling Multimodal Foundation Models
@complete_ai
• слои, обработчики для разных модальностей, лосс функции (Contrastive Loss, Codebook слои, Shifted-window Attention, Components for CLIP, Multimodal GPT, Multi Head Attention) • SoTA архитектуры (FLAVA, DETR, …) • скрипты обучения и инференса • примеры использованияВсё это позволит ставить быстрые и удобные эксперименты для обучения М2 моделей.
В довесок авторы сделали интересный пост о распределённом обучении (ссылка), где на примере модели FLAVA (мультимодальный late fusion трансформер) показали, как можно её масштабировать с 350M параметров до 10B. Рассмотрели два ключевых подхода:
1. Distributed Data Parallel - нарезка датасета по воркерам, градиенты синхронизируются ДО обновления весов, по сути вся модель «реплицируется»
2. Fully Sharded Data Parallel - параметры, градиенты и состояния оптимизатора нарезаются (шардируются) по воркерам (а-ля ZeRO-3), перед forward и backward propagation шарды объединяются.
Сравнение производительности (среднее число сэмплов в секунду за исключением первых 100 на warmup) можно оценить на графике.
github
статья про TorchMultimodal
статья про Scaling Multimodal Foundation Models
@complete_ai