MinD-Vis: диффузия для чтения мыслей
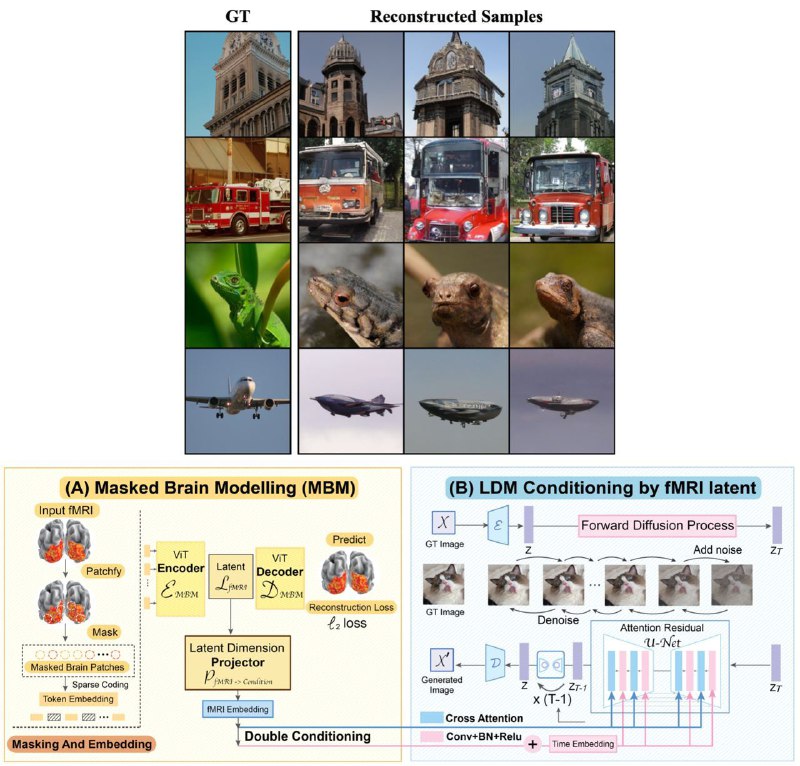
Представлена диффузионная модель, которая умеет декодировать то, что видит человек по его мозговой активности (fMRI).
Сначала авторы обучили self-supervised модель для получения универсальных эмбеддингов мозговой активности (одинаковых для разных людей). Далее они взяли предобученную Latent Diffusion и добавили к ней cross-attention на эти мысленные репрезентации. После короткого файнтюна на 1.5к парах картинка-fMRI модель смогла полноценно декодировать то, что видит перед собой человек!
Данные для обучения и код выложены в открытый доступ, веса моделей дают по запросу.
Статья, GitHub, блог
Представлена диффузионная модель, которая умеет декодировать то, что видит человек по его мозговой активности (fMRI).
Сначала авторы обучили self-supervised модель для получения универсальных эмбеддингов мозговой активности (одинаковых для разных людей). Далее они взяли предобученную Latent Diffusion и добавили к ней cross-attention на эти мысленные репрезентации. После короткого файнтюна на 1.5к парах картинка-fMRI модель смогла полноценно декодировать то, что видит перед собой человек!
Данные для обучения и код выложены в открытый доступ, веса моделей дают по запросу.
Статья, GitHub, блог