Typical sampling: идеальный метод генерации текста
Языковые модели (например GPT) предсказывают распределение вероятностей следующего токена, но способов генерации текста из этих распределений очень много и у всех свои недостатки — зацикленность, скучность и даже «галлюцинации».
Оказалось, что главная проблема всех прежних подходов в том, что они ориентировались на перплексию текста и вероятность токенов, а нужно было на условную энтропию — это следует из информационной теории речи. Новый подход позволяет генерировать гораздо более связный, интересный и «человеческий» текст.
Но самое крутое — этот метод уже интегрирован в
Подробнее можно почитать тут.
Статья, GitHub
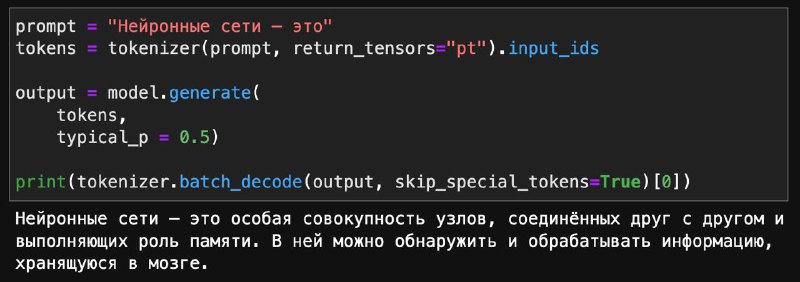
Языковые модели (например GPT) предсказывают распределение вероятностей следующего токена, но способов генерации текста из этих распределений очень много и у всех свои недостатки — зацикленность, скучность и даже «галлюцинации».
Оказалось, что главная проблема всех прежних подходов в том, что они ориентировались на перплексию текста и вероятность токенов, а нужно было на условную энтропию — это следует из информационной теории речи. Новый подход позволяет генерировать гораздо более связный, интересный и «человеческий» текст.
Но самое крутое — этот метод уже интегрирован в
transformers! Нужно всего лишь добавить параметр генерации typical_p. Чем ниже этот параметр, тем более knowledgeable будет текст, а чем выше, тем более интересным и непредсказуемым.Подробнее можно почитать тут.
Статья, GitHub