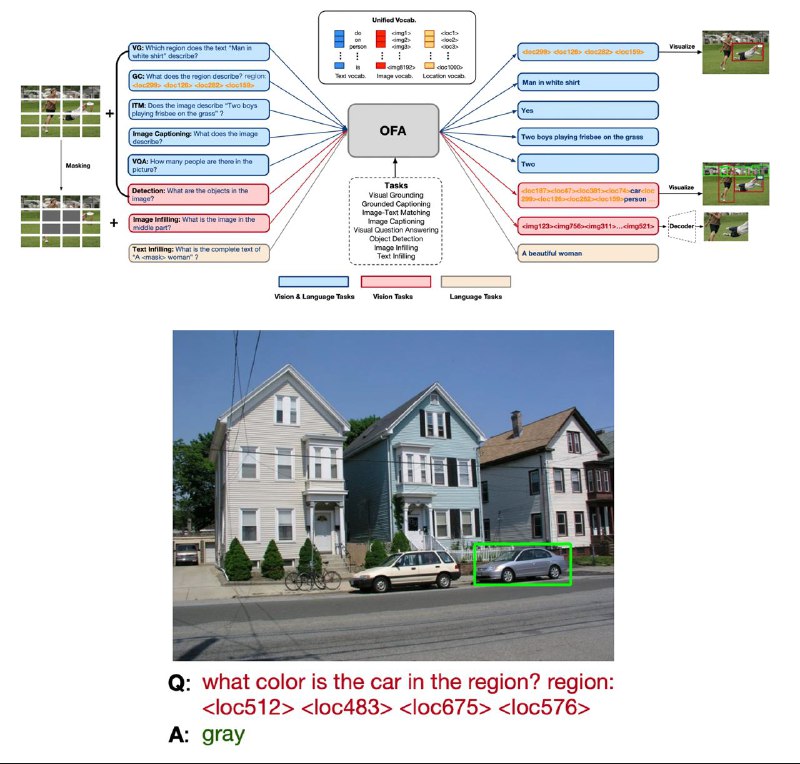
OFA: нужно лишь спросить
One For All — мультимодальная модель от Alibaba, которая умеет решать практически все CV-NLP задачи:
- text2image generating
- image captioning
- image inpainting
- VQA
- object detection
- NLU
Мало того, что она побила кучу сот, но и впервые для переключения между задачами не требуется совсем никаких архитектурных изменений (как во Florence). Нужно всего лишь текстом указать что мы хотим: «Закрась центр картинки» или «Что находится в *координаты куска картинки*?». Но САМОЕ крутое здесь это то, что модель смогла обобщиться на новые задачи, которых не было во время обучения — главное правильно сформулировать, что от неё требуется.
Технические детали:
Это энкодер-декодер архитектура — гибрид VQVAE и BART. Для слов, координат и визуальных токенов используется общий словарь репрезентаций, благодаря чему можно произвольно комбинировать модальности. Обучается это всё только на общедоступных данных, за что отдельный респект.
Статья, GitHub, colab
One For All — мультимодальная модель от Alibaba, которая умеет решать практически все CV-NLP задачи:
- text2image generating
- image captioning
- image inpainting
- VQA
- object detection
- NLU
Мало того, что она побила кучу сот, но и впервые для переключения между задачами не требуется совсем никаких архитектурных изменений (как во Florence). Нужно всего лишь текстом указать что мы хотим: «Закрась центр картинки» или «Что находится в *координаты куска картинки*?». Но САМОЕ крутое здесь это то, что модель смогла обобщиться на новые задачи, которых не было во время обучения — главное правильно сформулировать, что от неё требуется.
Технические детали:
Это энкодер-декодер архитектура — гибрид VQVAE и BART. Для слов, координат и визуальных токенов используется общий словарь репрезентаций, благодаря чему можно произвольно комбинировать модальности. Обучается это всё только на общедоступных данных, за что отдельный респект.
Статья, GitHub, colab