🔥InstructGPT: новое поколение GPT от OpenAI
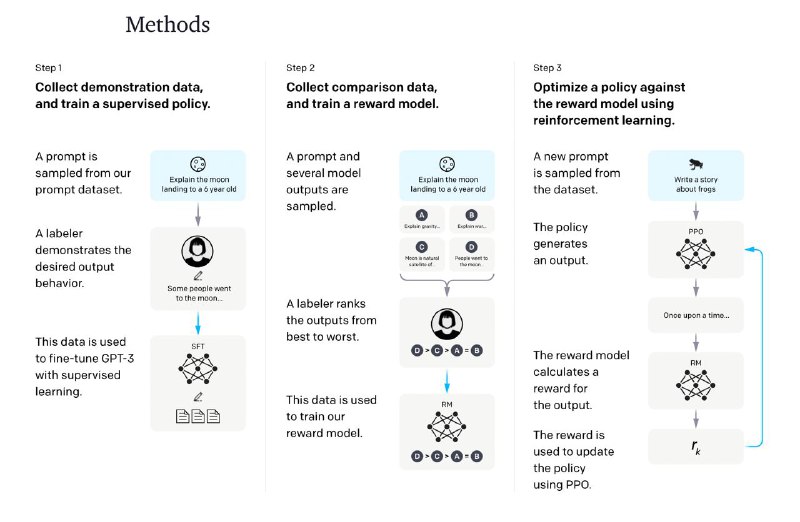
Архитектурно это всё та же GPT-3, вся фишка в дообучении:
1. Сначала, они её немного зафайнтюнили на чистых данных.
2. Потом вручную разметили качество получающихся аутпутов и обучили reward модель его предсказывать.
3. Далее в ход пошёл Reinforcement Learning алгоритм (PPO), который по этой reward модели ещё чуть-чуть затюнил GPT.
В итоге InstructGPT стала менее токсичной, реже путается в фактах и в целом лучше справляется со всеми задачами. Говорят, что даже 1.3B новая модель лучше, чем 175B старая.
P.S. Похоже, что RL теперь снова в моде благодаря языковым моделям.
Статья, блог, GitHub
Архитектурно это всё та же GPT-3, вся фишка в дообучении:
1. Сначала, они её немного зафайнтюнили на чистых данных.
2. Потом вручную разметили качество получающихся аутпутов и обучили reward модель его предсказывать.
3. Далее в ход пошёл Reinforcement Learning алгоритм (PPO), который по этой reward модели ещё чуть-чуть затюнил GPT.
В итоге InstructGPT стала менее токсичной, реже путается в фактах и в целом лучше справляется со всеми задачами. Говорят, что даже 1.3B новая модель лучше, чем 175B старая.
P.S. Похоже, что RL теперь снова в моде благодаря языковым моделям.
Статья, блог, GitHub