data2vec: Self-supervised Learning in Speech, Vision and Language (by Meta AI)
Картинки, звук, текст — три основные модальности данных. Большинство исследований концентрируются на какой-то одной из них: ViT, HuBERT, BERT, ведь не ясно как можно унифицировать обучение для всех трёх сразу.
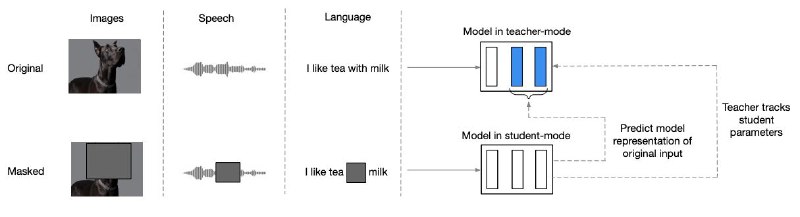
В Meta AI придумали как уйти от специфичности конкретного формата данных и учить модель понимать вообще что угодно. Если коротко, то они предлагают «самодистиллировать» внутренние репрезентации модели, да ещё и в self-supervised режиме.
Если углубиться чуть сильнее, то станет ясно, что предложенный метод очень похож на DINO. Тут есть две модели: студент и учитель. Первая модель (студент) учится повторять активации второй модели из частично замаскированного инпута, а учитель — это экспоненциально сглаженные по времени веса студента.
Оказалось, что самый обыкновенный трансформер, обученный таким способом, показывает крутейшие результаты на каждой из трёх модальностей по отдельности.
Статья, GitHub
Картинки, звук, текст — три основные модальности данных. Большинство исследований концентрируются на какой-то одной из них: ViT, HuBERT, BERT, ведь не ясно как можно унифицировать обучение для всех трёх сразу.
В Meta AI придумали как уйти от специфичности конкретного формата данных и учить модель понимать вообще что угодно. Если коротко, то они предлагают «самодистиллировать» внутренние репрезентации модели, да ещё и в self-supervised режиме.
Если углубиться чуть сильнее, то станет ясно, что предложенный метод очень похож на DINO. Тут есть две модели: студент и учитель. Первая модель (студент) учится повторять активации второй модели из частично замаскированного инпута, а учитель — это экспоненциально сглаженные по времени веса студента.
Оказалось, что самый обыкновенный трансформер, обученный таким способом, показывает крутейшие результаты на каждой из трёх модальностей по отдельности.
Статья, GitHub