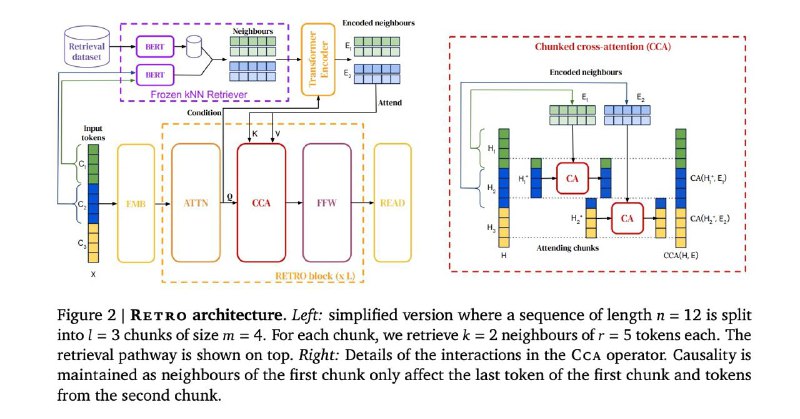
DeepMind вчера выпустили сетку Gopher на 280 миллиардов параметров (что впечатляет). Судя по их же примерам в релизе, Gopher очень хорошо может отвечать на фактологические вопросы ('Who won Womes's US Open in 2021', 'What can you tell me about cell biology'). Если заглянуть в статью с описанием архитектуры модели окажется, что это достигается не за счет числа параметров, а скорее за счет доступа к огромной базе знаний, то есть сетка частично retrieval based. Для сопоставления с базой данных берут замороженный BERT, получают эмбеддинги входного текста и эмбеддинги из базы знаний, находят ближайших соседей (и потом их используют на этапе аттеншена). Для базы данных используют MassiveText (5 триллионов токенов)
Еще для эффективности обучения используют chunked cross-attention, но под модификацию аттеншенов уже пора отдельный жанр на архиве заводить
Еще для эффективности обучения используют chunked cross-attention, но под модификацию аттеншенов уже пора отдельный жанр на архиве заводить