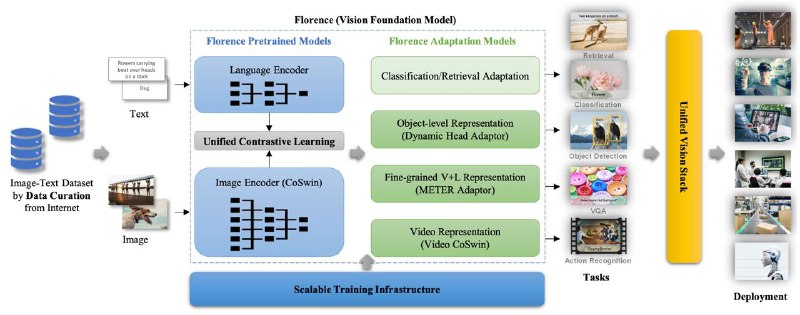
Florence: A New Foundation Model for Computer Vision (by Microsoft)
Очередная попытка создать универсальную visual модель, которая умеет почти всё и сразу:
- image classification,
- object detection,
- image/video retrieval,
- video action recognition,
- visual question answering.
И практически везде SOTA.
Рецепт Florence: собрать франкенштейна из CLIP+SWIN+DETR+METER и обучить на 900М пар картинок и текстов из интернета + все публичные датасеты на object detection.
Статья
Очередная попытка создать универсальную visual модель, которая умеет почти всё и сразу:
- image classification,
- object detection,
- image/video retrieval,
- video action recognition,
- visual question answering.
И практически везде SOTA.
Рецепт Florence: собрать франкенштейна из CLIP+SWIN+DETR+METER и обучить на 900М пар картинок и текстов из интернета + все публичные датасеты на object detection.
Статья