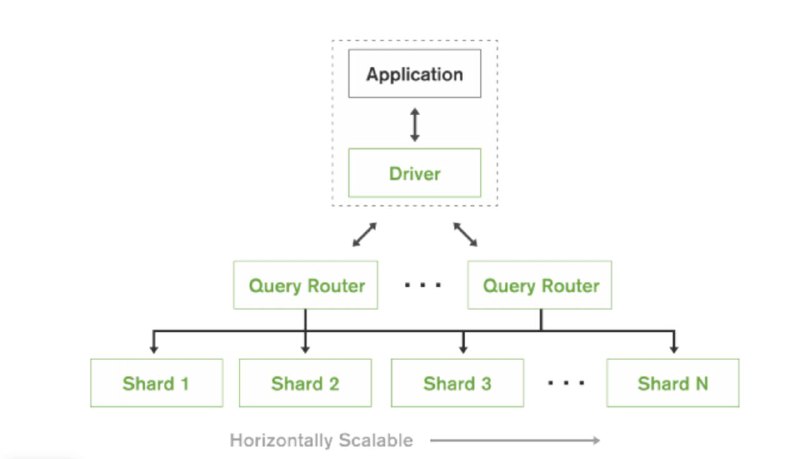
⚡Application-level sharding
Метод распределения данных между несколькими серверами БД, где логика распределения хранится на уровне приложения. При этом само хранилище может ничего не знать про шардирование
Логика работы:
1. Выбираем ключ шардирования
2. Определяем правила раутинга — как по ключу шардирования понять, на какой шард нужно отправить запрос
3. Приложению нужно исполнить некоторый запрос в БД
4. По запросу определяем, на какой(-ие) шард(-ы) его нужно отправить
Самое сложное — правильно выбрать ключ шардирования и правила раутинга, потому что
1. Важно, чтобы было по минимуму читающих запросов, задействующих >1 шардов
2. Важно, чтобы не было изменяющих запросов, задействующий >1 шардов. Поскольку в таком случае у нас теряется транзакционность, и нужно решать проблему распределенных транзакций
3. Менять ключ шардирования и правила раутинга очень больно
Ключом может быть, например, id главной сущности в системе, к которой привязываются все остальные
Определив ключ шардирования нужно определить правила раутинга. Здесь можно выделить
1. Stateless подход — грубо говоря, когда правила раутинга задаются чистой функцией, не зависящей от состояния системы. Например, выбор шарда определяется как hash(entityId) % n, где n - фиксированное число шардов
2. Stateful подход — есть некоторое изменяемое хранилище метаданных, которое определяет, куда раутить запросы по определенным ключам. Например, таблица с динамически расширяющимися диапазонами: по entityId от 0 до 9999 идем в шард 1, по entityId от 10000 до 19999 идем в шард 2, и тд. Правила могут динамически добавлятся, что позволяет управлять нагрузкой, если к примеру мощности шардов не одинаковые
Метод распределения данных между несколькими серверами БД, где логика распределения хранится на уровне приложения. При этом само хранилище может ничего не знать про шардирование
Логика работы:
1. Выбираем ключ шардирования
2. Определяем правила раутинга — как по ключу шардирования понять, на какой шард нужно отправить запрос
3. Приложению нужно исполнить некоторый запрос в БД
4. По запросу определяем, на какой(-ие) шард(-ы) его нужно отправить
Самое сложное — правильно выбрать ключ шардирования и правила раутинга, потому что
1. Важно, чтобы было по минимуму читающих запросов, задействующих >1 шардов
2. Важно, чтобы не было изменяющих запросов, задействующий >1 шардов. Поскольку в таком случае у нас теряется транзакционность, и нужно решать проблему распределенных транзакций
3. Менять ключ шардирования и правила раутинга очень больно
Ключом может быть, например, id главной сущности в системе, к которой привязываются все остальные
Определив ключ шардирования нужно определить правила раутинга. Здесь можно выделить
1. Stateless подход — грубо говоря, когда правила раутинга задаются чистой функцией, не зависящей от состояния системы. Например, выбор шарда определяется как hash(entityId) % n, где n - фиксированное число шардов
2. Stateful подход — есть некоторое изменяемое хранилище метаданных, которое определяет, куда раутить запросы по определенным ключам. Например, таблица с динамически расширяющимися диапазонами: по entityId от 0 до 9999 идем в шард 1, по entityId от 10000 до 19999 идем в шард 2, и тд. Правила могут динамически добавлятся, что позволяет управлять нагрузкой, если к примеру мощности шардов не одинаковые