⚡Quad-trees в гео-приложениях
Пост про geohash хорошо зашел, поэтому сегодня поговорим про еще один подход к индексированию гео-данных - Quad-trees
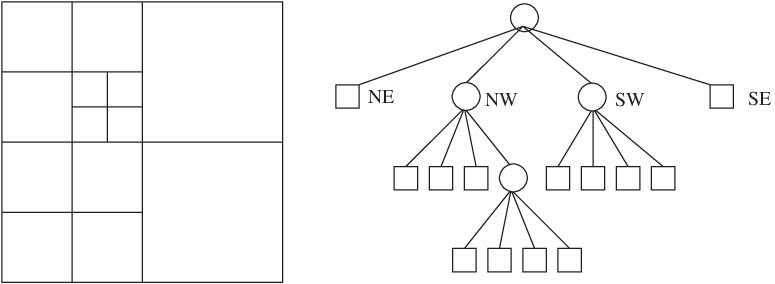
Суть подхода также заключается в рекурсивном делении пространства: пространство делится на 4 квадранта, каждый из которых либо остается as is, либо делится еще на 4 квадранта и так далее. В итоге это можно представить в виде дерева, где каждый внутренний узел имеет ровно 4 потомка. Позиция точки определяется тем, к какому "листовому квадранту" в дереве она принадлежит
Пока очень похоже на geohash: если бы мы делили пространство на 32 ячейки, и если все квадранты имели бы одинаковый размер, то он бы и получился, просто в формате дерева
--
Основная разница в том, что деревья квадрантов динамические:
1. Выбирается bucket size - максимальное число точек, которое может находится в определенном квадранте
2. При вставке новой точки в дерево проходимся по нему, находим нужный квадрант. Если там уже находится bucket size точек, то этот квадрант делится еще на 4, и точки распределяются по ним
--
Такая специфика может быть полезна в некоторых приложениях, например, поиск такси:
1. Позиции машин индексируются и складываются в quad tree (периодически обновляясь), допустим с bucket size = 5 - это значит, что в одном квадранте находится не более 5 машин
2. Когда человек вызывает такси, мы определяем, в каком квадранте он находится, и ищем машины именно в нем
Когда человек находится в какой-то глуши, искать энивей будем в одном квадранте, но по большой площади из-за низкой плотности машин. В то же время, когда человек вызывает такси в городе, искать будем уже по меньшей площади, потому что плотность машин сильно больше
Пост про geohash хорошо зашел, поэтому сегодня поговорим про еще один подход к индексированию гео-данных - Quad-trees
Суть подхода также заключается в рекурсивном делении пространства: пространство делится на 4 квадранта, каждый из которых либо остается as is, либо делится еще на 4 квадранта и так далее. В итоге это можно представить в виде дерева, где каждый внутренний узел имеет ровно 4 потомка. Позиция точки определяется тем, к какому "листовому квадранту" в дереве она принадлежит
Пока очень похоже на geohash: если бы мы делили пространство на 32 ячейки, и если все квадранты имели бы одинаковый размер, то он бы и получился, просто в формате дерева
--
Основная разница в том, что деревья квадрантов динамические:
1. Выбирается bucket size - максимальное число точек, которое может находится в определенном квадранте
2. При вставке новой точки в дерево проходимся по нему, находим нужный квадрант. Если там уже находится bucket size точек, то этот квадрант делится еще на 4, и точки распределяются по ним
--
Такая специфика может быть полезна в некоторых приложениях, например, поиск такси:
1. Позиции машин индексируются и складываются в quad tree (периодически обновляясь), допустим с bucket size = 5 - это значит, что в одном квадранте находится не более 5 машин
2. Когда человек вызывает такси, мы определяем, в каком квадранте он находится, и ищем машины именно в нем
Когда человек находится в какой-то глуши, искать энивей будем в одном квадранте, но по большой площади из-за низкой плотности машин. В то же время, когда человек вызывает такси в городе, искать будем уже по меньшей площади, потому что плотность машин сильно больше